
Large Language Models (LLMs) have effectively "soaked up" the collective knowledge of human history from the vast corpora they were trained on. To test the depth of this knowledge, I conducted an experiment: how does AI perceive the centuries-old heritage of Pune?
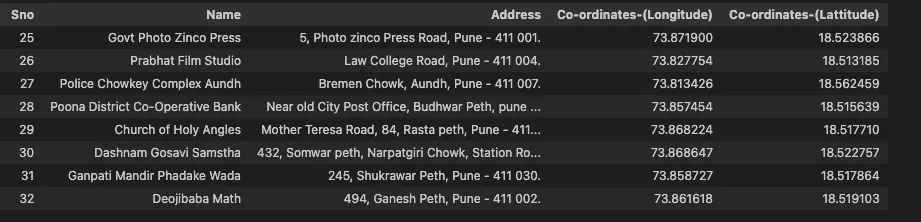
Using the heritage sites database provided by the Pune Municipal Corporation and the Digital India initiative, I analyzed 146 locations spanning from the 9th to the 20th century.
Step 1: Knowledge Extraction
We successfully mapped 77% of the dataset to corresponding Wikipedia pages. Using the Wikipedia API, we extracted detailed summaries to serve as the rich textual context for our analysis.
import wikipedia
def get_wiki_summary(x):
try:
# Extracting summary via page title from URL
return wikipedia.summary(x.split("/wiki/")[1])
except:
return ""
heritige_urls_df["wiki_summary"] = heritige_urls_df["article_url"].apply(get_wiki_summary)Step 2: Vectorization & Embeddings
To translate text into machine-understandable math, I employed two distinct embedding strategies to compare performance:
1. BERT-based Model
Utilized paraphrase-MiniLM-L6-v2 from HuggingFace. Yielded 384-dimensional vectors.
2. OpenAI Model
Utilized text-embedding-ada-002 via LangChain. Yielded 1586-dimensional vectors.
from sentence_transformers import SentenceTransformer
from langchain.embeddings import OpenAIEmbeddings
# Compiling context for the model
def compile_text(x):
return f"Name: {x['Name']}, Address: {x['Address']}, wiki_summary: {x['wiki_summary']}"
sentences = df.apply(compile_text, axis=1).tolist()
# Generating embeddings
model = SentenceTransformer("sentence-transformers/paraphrase-MiniLM-L6-v2")
output_hf = model.encode(sentences, normalize_embeddings=True)
embeddings_oi = OpenAIEmbeddings(openai_api_key="YOUR_KEY")
output_oi = [embeddings_oi.embed_query(x) for x in sentences]Step 3: Dimensionality Reduction & Clustering
With only 146 samples, high-dimensional vectors risk the "curse of dimensionality." I applied PCA (Principal Component Analysis) to condense the data while retaining 70% of the variance (30 dimensions for BERT, 50 for OpenAI).
Using the Elbow Method, I determined that k=3 was the optimal cluster size for meaningful interpretation across both models.
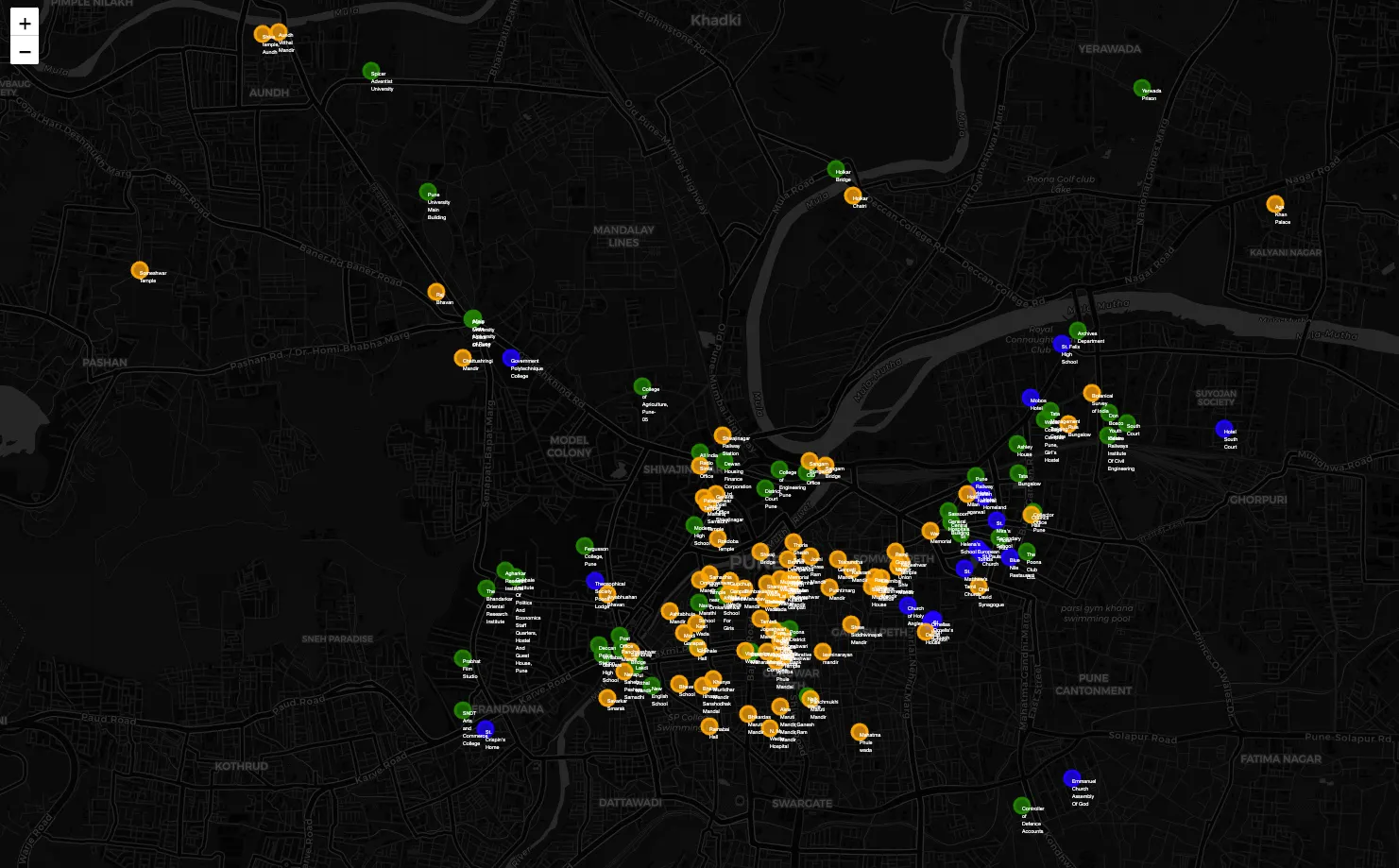
Analysis: The Three Faces of Pune
The AI effectively categorized the city into three distinct historical "epochs":
- Cluster 1 (Pre-1850): The era of Maratha influence, characterized by Wadas and ancient temples.
- Cluster 2 (British Era): Post-1850 transformation, featuring colonial architecture and "Raj" influences.
- Cluster 3 (Modern/Institutional): The proliferation of educational hubs (Deccan, Law College Rd) and government bodies.

An interesting nuance: The Brother Deshpande Memorial Church was grouped with ancient temples (Cluster 1) rather than colonial churches. Its location in Kasba Peth (the oldest part of the city) and its Indian namesake likely influenced the model to recognize its deep-rooted local history over its architectural category.
Conclusion
The experiment confirms that LLM embeddings capture more than just keywords—they capture contextual relationships. Even locations with identical addresses, like Chattushringi Mandir and Government Polytechnic, were correctly separated into historical vs. institutional clusters based on their Wikipedia narratives.
Explore the full interactive maps here or connect with me to discuss NLP and data science!
References:
- HuggingFace: paraphrase-MiniLM-L6-v2
- OpenData Pune Municipal Corporation
- Inspiration: "Mastering Customer Segmentation with LLM" (Towards Data Science)